- Published
Detecting Mental Health Conditions of Twitter Users using NLP
- Published
- Labib Alfaraby, Gaudhiwaa Hendrasto, and Surya Abdillah
Social media serves as a medium for people to express what they are feeling, doing, and facing. In this research, an experiment is conducted to perform text classification to predict whether social media users are experiencing stress or not by analyzing their tweets and comments. The stages in this research include data collection, data preprocessing, pseudo-labeling, topic extraction, and data categorization based on topics. The dataset containing Twitter user posts is used in developing the Bidirectional Encoder Representations (IndoBERT) model for stress classification. The development of LSTM and BiLSTM models is also conducted for comparison with the accuracy of IndoBERT. The best model obtained is IndoBERT with an accuracy of 66%. Subsequently, a model is developed to perform topic modeling on user posts to identify the topics of the issues experienced by users using BERTopic. The coherence result from topic modeling is 62%. This research is expected to be useful as one of the methods for detecting social media users' stress from their tweets. Through the categorization of mental health conditions in this tweet model, the results can be used as a reference for various public services related to mental health, such as mental health hotlines, counseling services, and mental health awareness campaigns.
Background
In this era of digitization, human dependence on technology is very close, especially in the use of mobile phones or smartphones. Smartphones have become a lifestyle in today's era, where activities from waking up to going to sleep are seemingly connected to smartphones. For example, when going to the office, we check the time through our smartphones, and when meeting friends, we communicate beforehand through the smartphones we own to determine the place and time to meet, and many other examples.
Social media is a must-have application on the smartphones of today's users; everyone who uses a smartphone surely has at least one registered social media account. Social media enables the connection between one user (known as followers and following) with another user, making virtual interactions highly possible. In social media, most users will share the activities they go through in a day, either in the form of photo documentation or written expressions. The reactions they show are diverse, ranging from moments of joy and happiness to feelings of sadness and anxiety. Therefore, social media serves as a platform for everyone to express and show their feelings or thoughts. The most influential factors in spreading information on social media are personal factors, namely ability and motivation, as well as environmental factors, namely the strength of ties on social media networks (Hapsari, Nurul Fiktirati Ayu, 2020).
Stress is one of the conditions often depicted in social media posts. Stress itself is a mental and emotional disorder caused by external factors. The American Psychological Association (APA, 2012) study has shown that millennials (ages 18 to 33) have the highest average stress level, which is 5.4, exacerbated by the lack of ability to manage stress. The age group of 18 to 33 in Indonesia can be classified as early adulthood, where individuals will face various emotional problems in their lives. On the other hand, despite the stressful condition, this early adult category also has significant responsibilities as agents of change and influences the development and progress of the nation. Therefore, an effort to address stress as soon as possible is needed for the development and progress of Indonesia.
Objectives
Based on the background above, the objectives of the social media user stress prediction research are as follows:
Understand the stress conditions of social media users.
Build a Natural Language Processing (NLP) model to predict the stress conditions of users in social media posts.
Benefits
The results of this research are expected to bring benefits to researchers, readers, the community, and the government, as explained below:
a. Researchers
This research serves as one way for researchers to explore new knowledge and enhance motivation for research and creativity.
b. Readers
This research can serve as a foundation and inspiration for other researchers to develop further studies.
c. Community
- The results of this research can be used as one method to detect stress from tweets.
- The results of this research can provide a better understanding of the stress conditions of social media users.
Problem Limitations
The limitations and issues in this research are as follows:
Data collected is limited to the Twitter social media platform. Data collection is carried out on Twitter using keywords related to stress.
The focus of the analysis is limited to Indonesian language text posts on social media that indicate user stress conditions. The analysis does not involve visual elements such as images or videos.
Methodology
Based on the literature review conducted, a series of research processes were arranged to achieve the objectives of this study, as shown in Figure below.

Data Collection
Data collection was carried out by searching Twitter using the snscrape library. The purpose of data collection is to obtain tweets from users experiencing stress. The keywords used for data collection include: tired, anxious, self-harm, trauma, not passed, thesis exhaustion, dating distress, lack of sleep. The total collected data is 1823 rows, consisting of link and tweet columns.
Preprocessing
After the data is collected, preprocessing is performed to optimize model creation. The preprocessing steps include: a. Case folding: changing text to lowercase b. Removal of unused parts: removing emojis, hashtags, mentions, and links in tweets c. Handling slang words: changing slang words to formal words using a slang dictionary d. Stemming: the process of changing words to their base form e. Change stopwords: removing less important words f. Slang remover: changing or removing slang words g. Data filtering: removing words with fewer than 3 letters and deleting data with fewer than 5 words
Topic Labeling
Topic labeling is performed to categorize tweets as stress-related. The steps in this process include:
- Manual stress labeling for a portion of the preprocessed data.
- Building prediction models using LSTM, BiLSTM, and IndoBERT methods on labeled data.
- Predicting stress labels with the LSTM, BiLSTM, and IndoBERT models.
- Model evaluation.
Topic Modeling
Data predicted by the model with the best evaluation score in the pseudo-labeling step will be used in the topic extraction process. The method used is BERTopic, involving 5 main steps: embed documents, dimensionality reduction, cluster documents, bag-of-words, and topic representation. After obtaining topics from the BERTopic model, an evaluation will be conducted using the coherence score. The list of words in the topic with the best coherence score will be used as a reference for determining stress categories and then used as a model to categorize each document with the corresponding topic.
Results and Discussion
In this study, 2000 data points were collected from Twitter using specific keywords to obtain tweets relevant to users' mental health conditions. After preprocessing, 1823 data points were ready for further analysis. To process these tweets, several steps were taken, including removing duplicate data, case folding, text cleaning, removing common words (stopword removal), links, and stemming. Examples of results before and after preprocessing can be seen in Table 2.
| No. | Tweet Link | Text Before Preprocessing | Text After Preprocessing |
|---|---|---|---|
| 1 | https://twitter.com/jji ... | It's okay, whoever is willing to accompany Hanbin's birthday live later (even if it's short, I don't mind). It's chaotic seeing them arrive at the airport last night, such chaos. Trauma a bit, for sure, especially for the maknaes. All those fans at the airport are arrogant. | I'm okay to accompany Hanbin's live birthday even if it's short; I don't mind. It's chaotic seeing them arrive at the airport last night, such chaos. A bit of trauma, especially for the maknaes. Arrogant fans at the airport. |
| 2 | https://twitter.com/ser ... | I'm stressed 😭😭😭 it's H-2 to the deadline, but still not enough, lol | I'm stressed, laughing at the deadline |
During the labeling process, we manually labeled 1556 data. The "stress" column is used to store label values, which can be 1 or 0. The value 1 indicates that the tweet is from a user experiencing stress, while the value 0 indicates that the tweet is from a user not experiencing stress.
Next, pseudo-labeling was performed on the remaining data. Pseudo-labeling was done using LSTM (Long Short-Term Memory), BiLSTM (Bidirectional LSTM), and BERT (Bidirectional Encoder Representations from Transformers) techniques. These techniques were used to obtain the best accuracy in predicting whether users are in a stressful state or not, and to add data of 1 or 0 in the "stress" column. The accuracy values for LSTM, BiLSTM, and IndoBERT models were 0.644, 0.613, and 0.681, respectively.
The predicted data from the IndoBERT model will be combined with manually labeled data. From this data, labeled stress data will be used to determine stress categories using BERTopic. The distribution of words in the stress label can be seen in Figure below.

In topic labeling using BERTopic, testing of parameter values was conducted, and the results are shown in Table 2. The nr_topics parameter refers to the number of topics desired in the model. In one case, the number of topics used was 3, meaning the model would try to identify 3 different topics in the dataset. The min_topic_size parameter is the minimum allowed topic size. This means that topics with a size less than min_topic_size will be ignored. In one case, the minimum allowed topic size was 10, so if a topic had fewer than 10 relevant documents, that topic would not be considered. The coherence result is a metric used to measure the quality of interpretability (interpreting and understanding) of topics in the model. The coherence value ranges from 0 to 1, where a higher value indicates better coherence.
| nr_topics | min_topic_size | coherence |
|---|---|---|
| 3 | 10 | 0.3648 |
| 3 | 15 | 0.3670 |
| 3 | 20 | 0.3648 |
| nr_topics | min_topic_size | coherence |
|---|---|---|
| 4 | 10 | 0.6129 |
| 4 | 15 | 0.6190 |
| 4 | 20 | 0.5067 |
| nr_topics | min_topic_size | coherence |
|---|---|---|
| 5 | 10 | 0.6129 |
| 5 | 15 | 0.5680 |
| 5 | 20 | 0.6194 |
Among these parameters, nr_topics 5, min_topic_size 20, and coherence value 0.6194 were chosen. Although the nr_topics parameter, which represents the number of extracted topics, was set to 5, one topic with a value of -1 was obtained. This value of -1 indicates that the topic does not have strong meaning, so topics with a value of -1 will not be used. The result of the topic modeling process includes several topic categories shown in Figure below. The topic categories are divided into four, labeled as topics 0 to 3: trauma, self-harm, workload burden, and relationships.
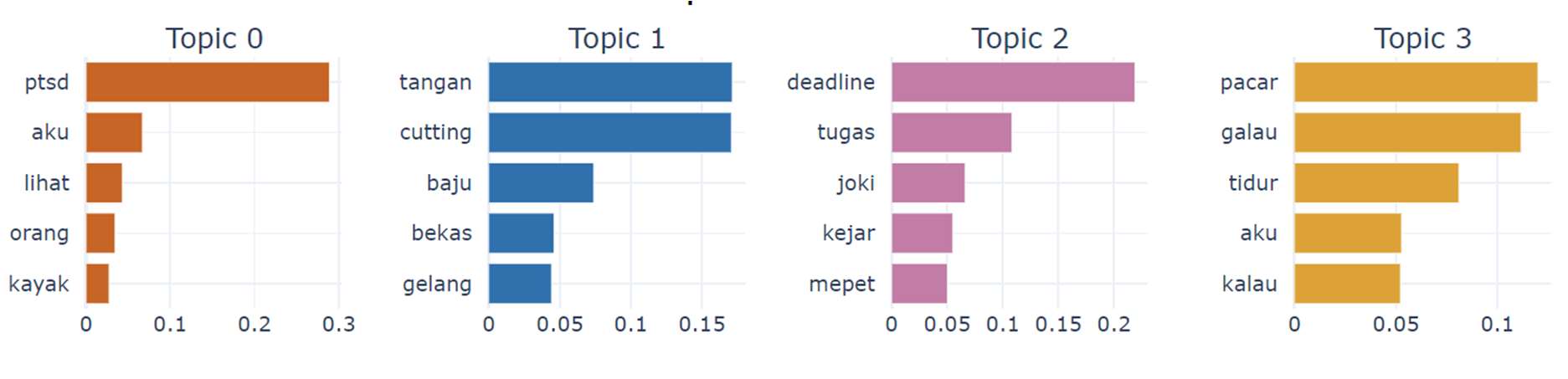
Using these four categories, stress category labeling was performed using BERTopic on tweet data. The results of the labeling can be seen in Table 4.
| No. | Topic Tweet | Topic |
|---|---|---|
| 1 | But lately, Bella seems to be very sad. Her snaps are very gloomy, and she posts photos of her parents. It seems like she has a lot on her mind. I don't dare to start a conversation unless she starts it because she's already married, not dating anymore. | relationship |
| 2 | I'm stressed 😭😭😭 it's H-2 deadline and still not enough hahaha workload burden | workload burden |
| 3 | But sometimes I feel embarrassed because there are cutting marks on my hands, so it's noticed a lot haha self-harm | self-harm |
| 4 | @lazsitude the last image triggers my PTSD. trauma | trauma |
Conclusion
This study introduces a method for analyzing contextual sentiment from tweets originating from the community regarding the mental health conditions of users in Indonesia. The data used in this study were obtained from Twitter, focused on obtaining mental health conditions. In the pseudo-labeling process, the accuracy for LSTM, BiLSTM, and IndoBERT models were 0.644, 0.613, and 0.681, respectively. Thus, it can be concluded that the IndoBERT model is the best model in predicting whether users are in a stressful condition, as it has the highest accuracy, namely 68%. This accuracy value may be considered low, but considering the small dataset, this model can be deemed quite good. Using the proposed method, BERTopic categorized tweets into trauma, self-harm, workload burden, and relationships, reflecting the mental health conditions of users. Moreover, the proposed method also recognized these three response types with a coherence level of 66%. The low accuracy and coherence rates are due to the limited dataset of 1823 data.
Through the categorization of mental health conditions in this tweet model, the results can be used as a reference for various public services related to mental health. For example, this categorization can be used as a guide in providing mental health hotlines accessible to the public for assistance and support. Additionally, the information contained in tweets can help counseling service providers better understand the needs and issues faced by the public. By utilizing the results of this categorization, campaigns for mental health awareness can also be designed more effectively and accurately, thereby increasing public understanding and support for mental health issues.
Bibliography
A. Kene and S. Thakare, "Mental Stress Level Prediction and Classification based on Machine Learning," 2021 Smart Technologies, Communication and Robotics (STCR), Sathyamangalam, India, 2021, pp. 1-7, doi: 10.1109/STCR51658.2021.9588803.
Ayu , N. I. F., Hapsari, Saleh, A., & Ardyawin, I. (2020). INFORMATION SHARING BEHAVIOUR DI MEDIA SOSIAL. Universitas Muhammadiyah Mataram, Vol 2, No 2 (2020): November. https://doi.org/10.31764/jiper.v2i2.3456
Baranwal, S. (2016, 7 Juli). Understanding BERT. Medium. Diakses 2 Juli 2023, dari https://pub.towardsai.net/understanding-bert-b69ce7ad03c1
Baranwal, S. (2020, 17 Februari). Understanding BERT. Medium. Diakses 2 Juli 2023, dari https://pub.towardsai.net/understanding-bert-b69ce7ad03c1
Geeksforgeeks (2023, 23 Maret). What is Web Scraping and How to Use It? Diakses 2 Juli 2023, dari https://www.geeksforgeeks.org/what-is-web-scraping-and-how-to-use-it/
Grootendorst, M. (2020, 5 Oktober). Topic Modelling with BERT. Medium. https://towardsdatascience.com/topic-modeling-with-bert-779f7db187e6
Horev, Rani. (2018, 11 November). BERT Explained: State of the art language model for NLP. Diakses 12 Juli 2023, dari https://towardsdatascience.com/bert-explainedstate- of-the-art-language-model-for-nlp-f8b21a9b6270
JustAnotherArchivist. (2020). snscrape. Diakses 2 Juli 2023, dari https://github.com/JustAnotherArchivist/snscrape
Katryn, R. G. (2023, 23 Maret). Text Preprocessing: Tahap Awal dalam Natural Language Processing (NLP). Diakses 2 Juli, 2023, dari https://medium.com/mandiriengineering/ text-preprocessing-tahap-awal-dalam-natural-language-processing-nlpbc5fbb6606a
Maarten. (2020). BERTopic. Diakses 2 Juli 2023, dari https://maartengr.github.io/BERTopic/index.html
Manaswi, N. K. (2018). Deep Learning with Applications Using Python (1st ed.). Apress.
Nijhawan, Tanya & Attigeri, Girija & Thalengala, Ananthakrishna. (2022). Stress detection using natural language processing and machine learning over social interactions.
Journal of Big Data. 9. 10.1186/s40537-022-00575-6.
Prakruthi Manjunath, Twinkle S, Pola Shreya, Vismaya Ashok, Dr. Shabana Sultana, 2021,
Predictive Analysis of Student Stress Level using Machine Learning,
INTERNATIONAL JOURNAL OF ENGINEERING RESEARCH & TECHNOLOGY (IJERT) NCCDS – 2021 (Volume 09 – Issue 12),
Prijono, B. (2018). Jaringan LSTM terdiri dari modul LSTM yang dipanggil secara berulang [Photograph]. https://Indoml.com/2018/04/13/Pengenalan-Long-Short-Term-Memory-
Lstm-Dan-Gated-Recurrent-Unit-Gru-Rnn-Bagian-2/. https://indoml.files.wordpress.com/2018/04/lstm.jpg
Rijcken, Emil. (2023, 3 Januari). Cv Topic Coherence Explained. Diakses 12 Juli 2023, dari https://towardsdatascience.com/c%E1%B5%A5-topic-coherence-explainedfc70e2a85227
Shenoy, A. (2019, 3 Desember). Pseudo-Labeling to deal with small datasets — What, Why & How?. Diakses 12 Jul 2023, dari https://towardsdatascience.com/pseudo-labelingto- deal-with-small-datasets-what-why-how-fd6f903213af
Sheridan, S. (2022, 16 November). What Is Topic Modeling? A Beginner's Guide. Diakses 2 Juli 2023, dari https://levity.ai/blog/what-is-topic-modeling
Singh, R. (2021, 4 Oktober). Topic Labeling. Diakses 2 Juli 2023, dari https://medium.com/nerd-for-tech/topic-labeling-16f0a1335450
Trivusi (2022, 17 September). Mengenal Algoritma Long Short Term Memory (LSTM). Diakses 2 Juli 2023, dari https://www.trivusi.web.id/2022/07/algoritma-lstm.html
WHO (2023, 21 Februari). Stress. World Health Organization. Diakses 2 Juli 2023, dari https://www.who.int/news-room/questions-and-answers/item/stress
Yosia, M. (2023, 14 April). Beda Eustress dan Distress serta Cara Menghadapinya. Diakses 2 Juli, 2023, dari https://hellosehat.com/mental/stres/eustress-dan-distress/